今天为啥又聊 Merkle Tree 呢? 我们地球上大部分人应该连它的名字都没有听过,而且说实话它也是个比较传统的概念了。Merkle Tree 是由计算机科学家 Ralph Merkle 在很多年前提出的,并以他本人的名字来命名。不过,Merkle Tree 确实涉及到了很多有意思的实际应用。最近几年才有的一个例子是,比特币钱包服务用 Merkle Tree 的机制来作”百分百准备金证明“ ( http://blog.bifubao.com/2014/03/16/proof-of-reserves/ )。不过今天,我们还是从数据的“完整性校验”这个角度来聊 Merkle Tree。 Git 版本控制系统,ZFS 文件系统以及我们自己下载电影常用的点对点网络 BT 下载,都是通过 Merkle Tree 来进行完整性校验的。顺便说一句,所谓的完整性校验,就是检查一下数据有没有损坏。

先说哈希( Hash )
其实要实现完整性校验,最简单的方法就是对要校验的整个的数据文件做个哈希运算,把得到的哈希值公布在网上,这样我们把数据下载到手之后,再次运算一下哈希值,如果运算结果相等,就表示我们下载过程中文件没有任何的损坏。因为哈希的最大特点是,如果你的输入数据,稍微变了一点点,那么经过哈希运算,你得到的哈希值将会变得面目全非。这样做的一个目的是可以防止有人根据哈希值反推出原始输入数据的一些特征。前面我录了一期视频专门关于哈希的,大家可以看看。
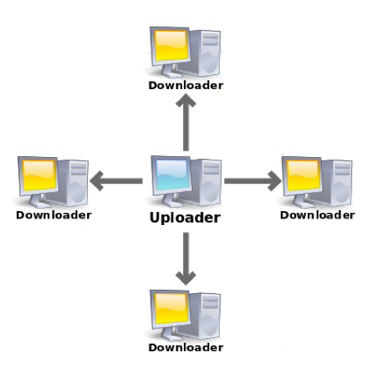
如果我们从一个稳定的服务器上进行下载,那么采用单个哈希来进行校验的形式是可以接受的。
再说哈希列表( Hash List )
但是在点对点网络中作数据传输的时候,我们会从同时从多个机器上下载数据,而且其中很多机器可以认为是不稳定或者是不可信的,这时需要有更加巧妙的做法。实际中,点对点网络在传输数据的时候,其实都是把比较大的一个文件,切成小的数据块。这样的好处是,如果有一个小块数据在传输过程中损坏了,那我只要重新下载这一个数据块就行了,不用重新下载整个文件。当然这就要求每个数据块都拥有自己的哈希值。BT 下载的时候,在下载真正的数据之前,我们会先下载一个哈希列表的。这时有一个问题就出现了,那么多的哈希,我们怎么保证它们本身都是正确地呢?
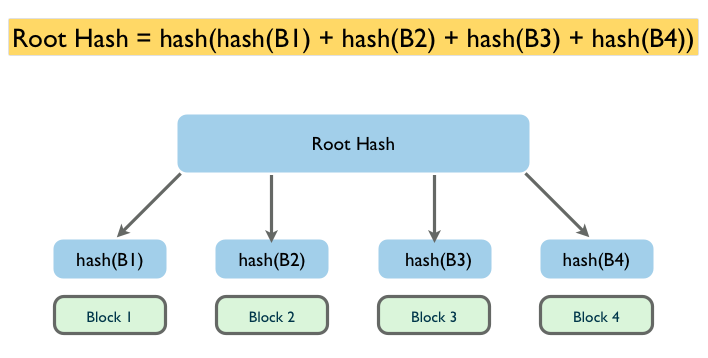
答案是我们需要一个根哈希。把每个小块的哈希值拼到一起,然后对整个这个长长的字符串再做一次哈希运算,最终的结果就是哈希列表的根哈希。于是,如果我们能够保证从一个绝对可信的网站,或者从我们的朋友手里拿到一个正确的根哈希,就可以用它来校验哈希列表中的每一 个哈希都是正确的,进而可以保证下载的每一个数据块的正确性了。
这种方式挺好,但是实际的应用中,其实还是有着它的不足之处的,这就是为什么 Merkle 教授要发明 Merkle Tree 了。
最后是 Merkle Tree
先看它的结构。
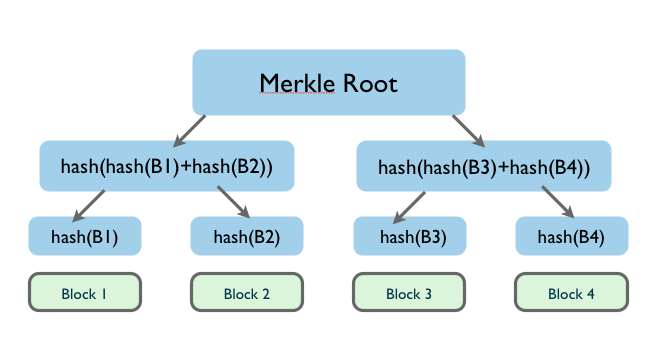
在最底层,和哈希列表一样,我们把数据分成小的数据块,有相应地哈希和它对应。但是往上走,并不是直接去运算根哈希,而是把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,这样每两个哈希就结婚生子,得到了一个”子哈希“。如果最底层的哈希总数是单数,那到最后必然出现一个单身哈希,这种情况就直接对它进行哈希运算,所以也能得到它的子哈希。于是往上推,依然是一样的方式,可以得到数目更少的新一级哈希,最终必然形成一棵倒挂的树,到了树根的这个位置,这一代就剩下一个根哈希了,我们把它叫做 Merkle root.
再说它的优点。
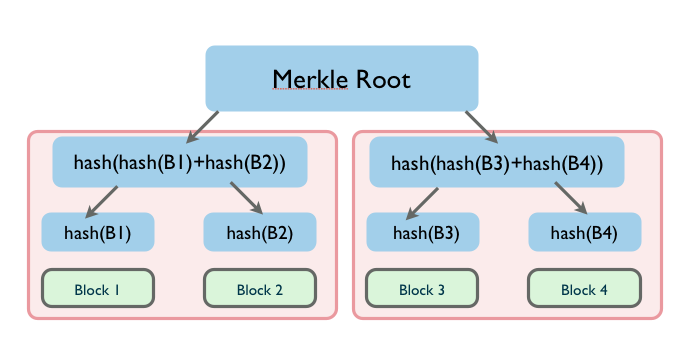
相对于 Hash List,Merkle Tree 的明显的一个好处是可以单独拿出一个分支来(作为一个小树)对部分数据进行校验,这个很多使用场合就带来了哈希列表所不能比拟的方便和高效。
好,这一期就说这么多,大家现在概念上有个认识,后面我们会有专门的文章讲 Merkle Tree 实用的例子。